Как мы валидировали нейросетевые прогнозы морского льда для конференции TITDS-2025
Введение: почему RMSE врёт Ссылка на заголовок
Представьте: вы обучили нейросеть прогнозировать морской лёд в Карском море. Метрика RMSE на тестовой выборке — 0.08. Красота. Вы пишете в статью «модель достигает RMSE 0.08 по концентрации льда», рецензент кивает, и все довольны.
А потом капитан ледокола на Северном морском пути смотрит на карту, построенную по вашему прогнозу, и видит чистую воду там, где реально стоит сплочённый лёд. Или наоборот — прокладывает маршрут в обход ледового поля, которого нет. Кромка льда — граница между «можно идти» и «нельзя идти» — уехала на 50 километров. А RMSE всё ещё 0.08.
Как такое возможно? Очень просто. RMSE — это среднее по всем пикселям. Если ваша модель идеально предсказывает открытую воду (90% площади летом) и идеально предсказывает сплошной лёд в центре Арктики, то ошибки на тонкой полоске кромки тонут в общей статистике. Вы получаете отличный RMSE и совершенно непригодный для навигации прогноз.
Это не гипотетическая проблема. Мы обнаружили, что почти 30% прогнозов, которые формально «проходят» по RMSE, дают кромку льда, непригодную для принятия навигационных решений. И это было не на какой-то экзотической модели — это стабильно воспроизводится на всех четырёх архитектурах, которые мы тестировали.
В этом посте — полный пайплайн валидации, который мы собрали для доклада на конференции TITDS-2025: от спутниковых данных до публикационных карт. Весь код — Python, numpy, matplotlib. Никаких ГИС-инструментов, никаких проприетарных библиотек. Всё, что нужно, помещается в один Colab-ноутбук.
Данные: OSI SAF и Карское море Ссылка на заголовок
Мы используем данные о концентрации морского льда (SIC) из продукта OSI SAF — это совместный проект метеослужб Норвегии, Дании, Финляндии, Швеции и Франции. Конкретно два датасета:
- CDR (Climate Data Record) — климатический архив, прошедший полный цикл валидации. Стабильный, но выходит с задержкой.
- ICDR (Interim CDR) — оперативный продукт, обновляется ежедневно, методологически совместим с CDR.
Оба датасета лежат на сетке EASE-Grid 2.0 с шагом 25 км. Это равноплощадная проекция — каждая ячейка покрывает ровно $625 , \text{км}^2$, что критически важно для подсчёта площадей. На широтно-долготной сетке площадь ячейки зависит от широты, и вы получаете систематическую ошибку в метриках.
Область исследования — Карское море: $65°$–$82° \text{N}$, $55°$–$100° \text{E}$. Почему именно оно? Во-первых, это ключевой участок Северного морского пути. Во-вторых, здесь одна из самых динамичных ледовых обстановок в Арктике: тёплые атлантические воды с запада, пресноводный сток Оби и Енисея, полыньи, быстрые подвижки кромки. Если ваша модель работает здесь — она, скорее всего, будет работать везде.
Временной охват: 2019–2024. Разбиение:
- Тренировка: январь 2019 — ноябрь 2021
- Тест: январь 2022 — декабрь 2024
Три полных года на тест — это важно. Один год может быть аномальным, два — уже лучше, три — дают минимально статистически значимую выборку для сезонного анализа.
Модели: от наивного базелайна до ConvLSTM Ссылка на заголовок
Мы намеренно не гнались за SOTA. Цель — не побить рекорд, а показать, что проблема расхождения RMSE и кромки воспроизводится на разных архитектурах. Четыре модели, от простой к сложной:
Persistence — базелайн нулевой сложности: прогноз на завтра равен наблюдению за сегодня. Ноль обучаемых параметров. Звучит тупо, но на горизонте 1 день эту штуку на удивление трудно побить. На горизонте 7+ дней — конечно, деградирует.
LSTM — попиксельная рекуррентная сеть. Каждый пиксель — отдельный временной ряд, lookback 30 дней. Никакой пространственной информации — модель не знает, что соседние пиксели связаны. Это намеренное ограничение: мы хотим увидеть, что даёт «слепой» к пространству подход.
U-Net — классический encoder-decoder для сегментации. На вход — 10 последовательных кадров SIC как каналы. U-Net видит пространственные паттерны, но не имеет явной модели временной динамики — для него 10 кадров это просто 10 каналов, как RGB + альфа, только их десять.
ConvLSTM — свёрточная LSTM, которая обрабатывает последовательность 10 кадров с учётом и пространства, и времени. Теоретически — лучшее из обоих миров. На практике — самая капризная в обучении.
Все модели тренируются с MSE-лоссом по SIC. Это стандарт в литературе, и это часть проблемы — но об этом позже.
IIEE-декомпозиция: метрика, которая видит кромку Ссылка на заголовок
Метрику IIEE (Integrated Ice Edge Error) предложили Goessling et al. в 2016 году, и она стала стандартом для валидации прогнозов ледовой кромки. Идея элегантная.
Сначала бинаризуем SIC при пороге 15% — стандартный порог WMO для определения границы ледового покрова:
- $B_F(x, y) = 1$ если прогноз $\geq 0.15$, иначе $0$
- $B_R(x, y) = 1$ если эталон $\geq 0.15$, иначе $0$
Теперь считаем два типа ошибок:
- Over-prediction ($O$) — модель говорит «лёд», а там вода. False Positive.
- Under-prediction ($U$) — модель говорит «вода», а там лёд. False Negative.
Каждая ошибка измеряется в $\text{км}^2$: количество ошибочных пикселей умножаем на площадь ячейки (625 $\text{км}^2$ для нашей сетки).
IIEE декомпозируется на две компоненты:
$$\text{IIEE} = O + U$$
$$\text{AEE} = |O - U|$$
$$\text{ME} = 2 \cdot \min(O, U)$$
где $\text{AEE}$ (Absolute Extent Error) — ошибка общей площади, а $\text{ME}$ (Misplacement Error) — чистое смещение кромки. Проверка: $\text{IIEE} = \text{AEE} + \text{ME}$.
Ключевое наблюдение: если $\text{ME}/\text{IIEE} > 0.5$, значит модель правильно оценила площадь льда, но поставила его не туда. Кромка уехала, а площадь совпала. Именно это состояние и ловит наш пайплайн.
Вот код на Python, который считает всю декомпозицию:
import numpy as np
# forecast, reference — 2D-массивы SIC (0..1)
B_F = (forecast >= 0.15).astype(np.float32)
B_R = (reference >= 0.15).astype(np.float32)
FP = B_F * (1 - B_R) # over-prediction
FN = (1 - B_F) * B_R # under-prediction
O = FP.sum() * 625.0 # km², cell area on 25 km grid
U = FN.sum() * 625.0
IIEE = O + U
AEE = abs(O - U)
ME = 2 * min(O, U)
Десять строк. Никаких зависимостей кроме numpy. Скопируйте, вставьте в свой пайплайн — работает.
Маленькое замечание: 625.0 — это площадь одной ячейки EASE-Grid 2.0 на 25 км ($25 \times 25 = 625$). Если у вас другая сетка — подставьте свою площадь. Если сетка неравноплощадная — вам понадобится матрица площадей ячеек, и sum() заменится на взвешенную сумму.
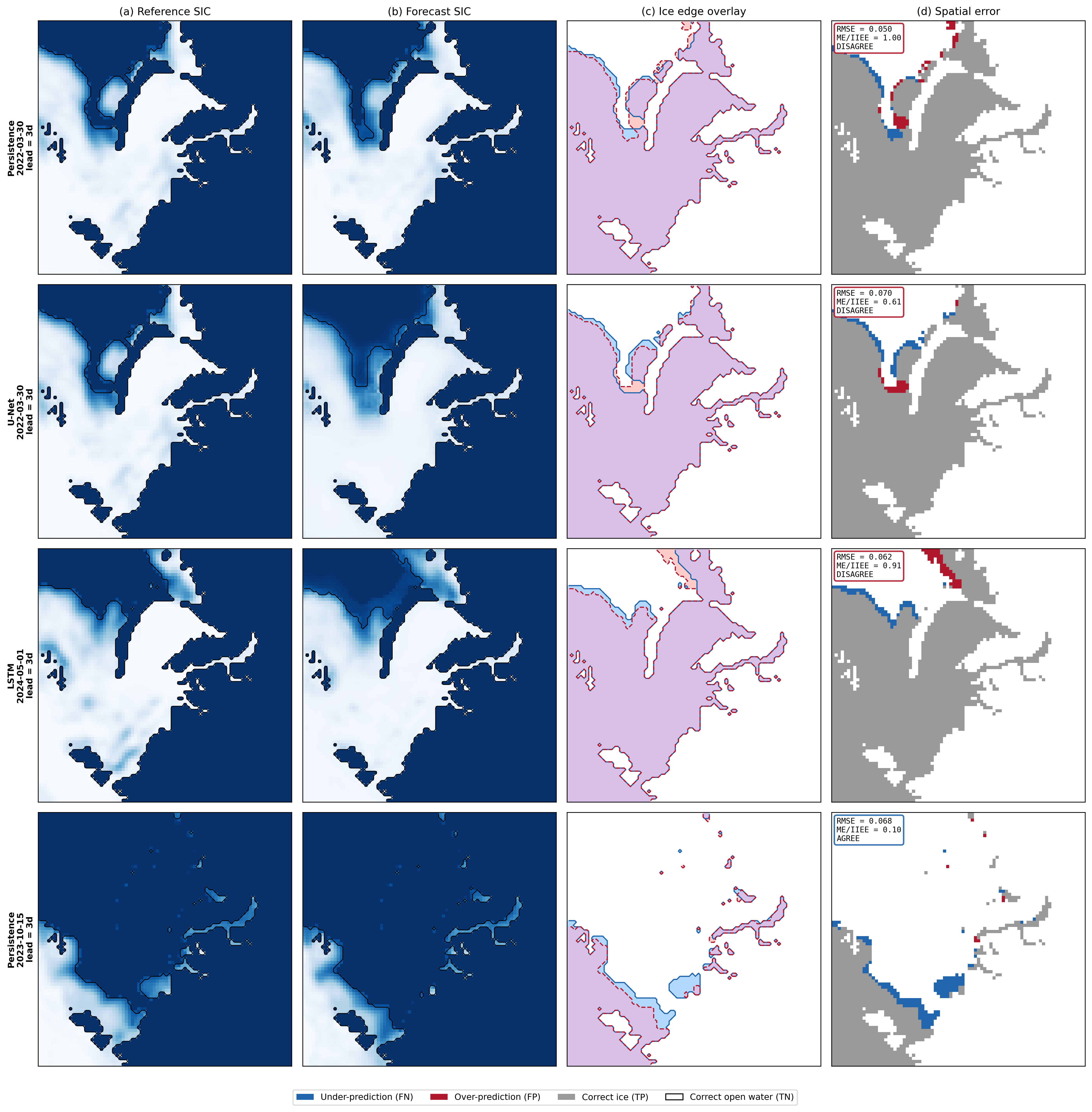
Визуализация: четыре панели, которые рассказывают всю историю Ссылка на заголовок
Это самая важная часть пайплайна. Одна четырёхпанельная фигура показывает всё, что нужно знать о конкретном прогнозе: где лёд, где ошибки, где кромка уехала. Рецензент видит её — и всё понимает без текста.
Разберём каждую панель.
Панель (a): Reference SIC — что видит спутник Ссылка на заголовок
import matplotlib.pyplot as plt
fig, axes = plt.subplots(1, 4, figsize=(20, 5))
ax = axes[0]
ax.imshow(reference, cmap='Blues_r', vmin=0, vmax=1, origin='lower')
ax.contour(B_R, levels=[0.5], colors='navy', linewidths=1.5)
ax.set_title('(a) Reference SIC')
Blues_r — обратная синяя палитра: белый = вода (SIC ~ 0), тёмно-синий = сплошной лёд (SIC ~ 1). Почему обратная? Потому что на картах льда лёд традиционно тёмный, а вода светлая. Попробуйте прямую Blues — будет интуитивно наоборот.
contour(B_R, levels=[0.5]) рисует кромку льда — изолинию бинарной маски при 0.5. Поскольку маска содержит только 0 и 1, контур при 0.5 проходит ровно по границе.
Важная деталь: origin='lower' — чтобы ось Y шла снизу вверх. Без этого карта будет перевёрнутой, юг окажется сверху.
Панель (b): Forecast SIC — что предсказала модель Ссылка на заголовок
ax = axes[1]
ax.imshow(forecast, cmap='Blues_r', vmin=0, vmax=1, origin='lower')
ax.contour(B_F, levels=[0.5], colors='darkred', linewidths=1.5)
ax.set_title('(b) Forecast SIC')
Абсолютно тот же код, только данные — прогноз, и контур красный. Визуальное сравнение (a) и (b) уже даёт интуицию: если синие поля похожи — модель в целом справилась. Но дьявол в деталях кромки, и для этого нужна панель (c).
Панель (c): Ice edge overlay — наложение кромок Ссылка на заголовок
Это самая информативная панель. Здесь мы строим RGB-изображение вручную, без colormap:
overlay = np.ones((*reference.shape, 3)) # white background
# Reference ice: light blue
ref_mask = B_R.astype(bool)
overlay[ref_mask] = [0.7, 0.85, 1.0]
# Forecast ice: light red
frc_mask = B_F.astype(bool)
overlay[frc_mask] = [1.0, 0.8, 0.8]
# Overlap: purple
both = ref_mask & frc_mask
overlay[both] = [0.85, 0.75, 0.9]
ax = axes[2]
ax.imshow(overlay, origin='lower')
ax.contour(B_R, levels=[0.5], colors='blue', linewidths=1.5,
linestyles='solid')
ax.contour(B_F, levels=[0.5], colors='red', linewidths=1.5,
linestyles='dashed')
ax.set_title('(c) Ice Edge Overlay')
Три цвета: голубой — лёд только в эталоне (модель пропустила, under-prediction), розовый — лёд только в прогнозе (модель придумала, over-prediction), фиолетовый — совпадение. Плюс два контура: сплошная синяя линия — эталонная кромка, пунктирная красная — прогнозная.
Зазор между линиями — это ME. Чем он шире, тем хуже. Цвет заливки показывает, в какую сторону ошибка. На хорошем прогнозе вы видите тонкую фиолетовую полоску с почти совпадающими контурами. На плохом — широкую розовую или голубую полосу с разнесёнными линиями.
Обратите внимание: никакого ГИС не нужно. Это просто numpy-массив формы $(H, W, 3)$, поданный в imshow. «Карта» получается автоматически, потому что данные уже лежат на равноплощадной сетке. Координатные оси — индексы пикселей. Для публикации можно добавить lat/lon-тики через ax.set_xticks с пересчётом, но для визуального анализа они не нужны.
Панель (d): Error map — бинарная карта ошибок Ссылка на заголовок
from matplotlib.colors import ListedColormap
error_map = np.zeros_like(B_R, dtype=np.int8)
error_map[(B_R == 0) & (B_F == 0)] = 0 # TN: correct water
error_map[(B_R == 1) & (B_F == 0)] = 1 # FN: missed ice
error_map[(B_R == 0) & (B_F == 1)] = 2 # FP: false ice
error_map[(B_R == 1) & (B_F == 1)] = 3 # TP: correct ice
cmap_err = ListedColormap(['white', '#2166ac', '#b2182b', '#999999'])
ax = axes[3]
ax.imshow(error_map, cmap=cmap_err, vmin=0, vmax=3, origin='lower')
# Annotation
status = 'DISAGREE' if me_ratio > 0.5 else 'AGREE'
ax.annotate(f'RMSE={rmse:.3f}\nME/IIEE={me_ratio:.2f}\n{status}',
xy=(0.02, 0.98), xycoords='axes fraction',
va='top', fontsize=9,
bbox=dict(boxstyle='round', fc='wheat', alpha=0.8))
ax.set_title('(d) Error Map')
plt.tight_layout()
plt.savefig('validation_panel.png', dpi=150, bbox_inches='tight')
Четыре цвета, четыре состояния:
| Цвет | Код | Значение |
|---|---|---|
| Белый | 0 | TN — вода в обоих |
Синий #2166ac | 1 | FN — пропущенный лёд |
Красный #b2182b | 2 | FP — ложный лёд |
Серый #999999 | 3 | TP — совпавший лёд |
Аннотация в углу — квинтэссенция: RMSE, отношение $\text{ME}/\text{IIEE}$ и вердикт AGREE/DISAGREE. Если RMSE низкий, а статус DISAGREE — это тот самый случай, когда средняя метрика маскирует пространственную ошибку.
Цвета #2166ac и #b2182b — из палитры RdBu diverging, они хорошо различимы и в цветной печати, и на проекторе. Серый для TP — намеренно нейтральный: правильно предсказанный лёд не должен отвлекать внимание от ошибок.
Главный результат: 30% прогнозов врут Ссылка на заголовок
Мы прогнали все четыре модели на трёхлетнем тестовом периоде (2022–2024) и для каждого дневного прогноза посчитали: (1) проходит ли по RMSE (порог 0.10), (2) проходит ли по $\text{ME}/\text{IIEE}$ (порог 0.50).
Результат: 29.6% прогнозов (95% CI: 27.6–31.7%) проходят по RMSE, но проваливаются по ME/IIEE. То есть почти каждый третий «хороший» прогноз даёт кромку, сдвинутую настолько, что пространственная информация непригодна для навигации.
Разбивка по моделям:
| Модель | RMSE-pass, ME-fail (%) |
|---|---|
| Persistence | 22.1 |
| LSTM | 28.3 |
| U-Net | 35.4 |
| ConvLSTM | 32.7 |
U-Net — рекордсмен. И это логично: encoder-decoder архитектура с MSE-лоссом учится «размазывать» предсказание вокруг кромки. Вместо чёткой границы 0/1 она выдаёт плавный градиент 0.3–0.7 в зоне кромки. RMSE от этого снижается (средняя ошибка маленькая), а бинарная кромка при пороге 0.15 уезжает в сторону меньшей концентрации — в открытое море.
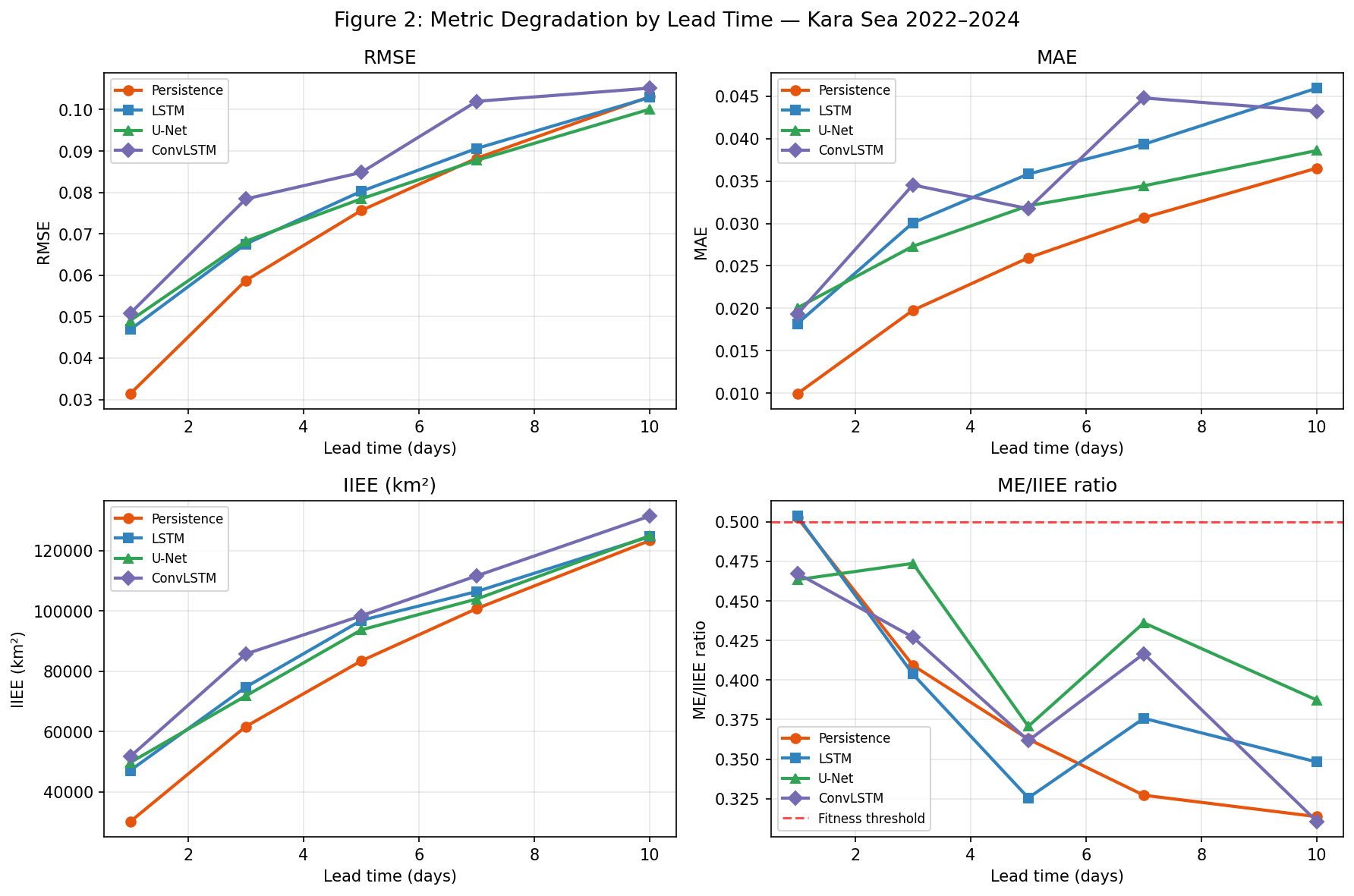
Эффект усиливается с увеличением горизонта прогноза. На рисунке выше видно, как расхождение между RMSE и IIEE растёт от 1 до 14 дней. На 1-дневном горизонте метрики ещё более-менее согласованы. На 7+ днях — RMSE остаётся приемлемым, а IIEE улетает.
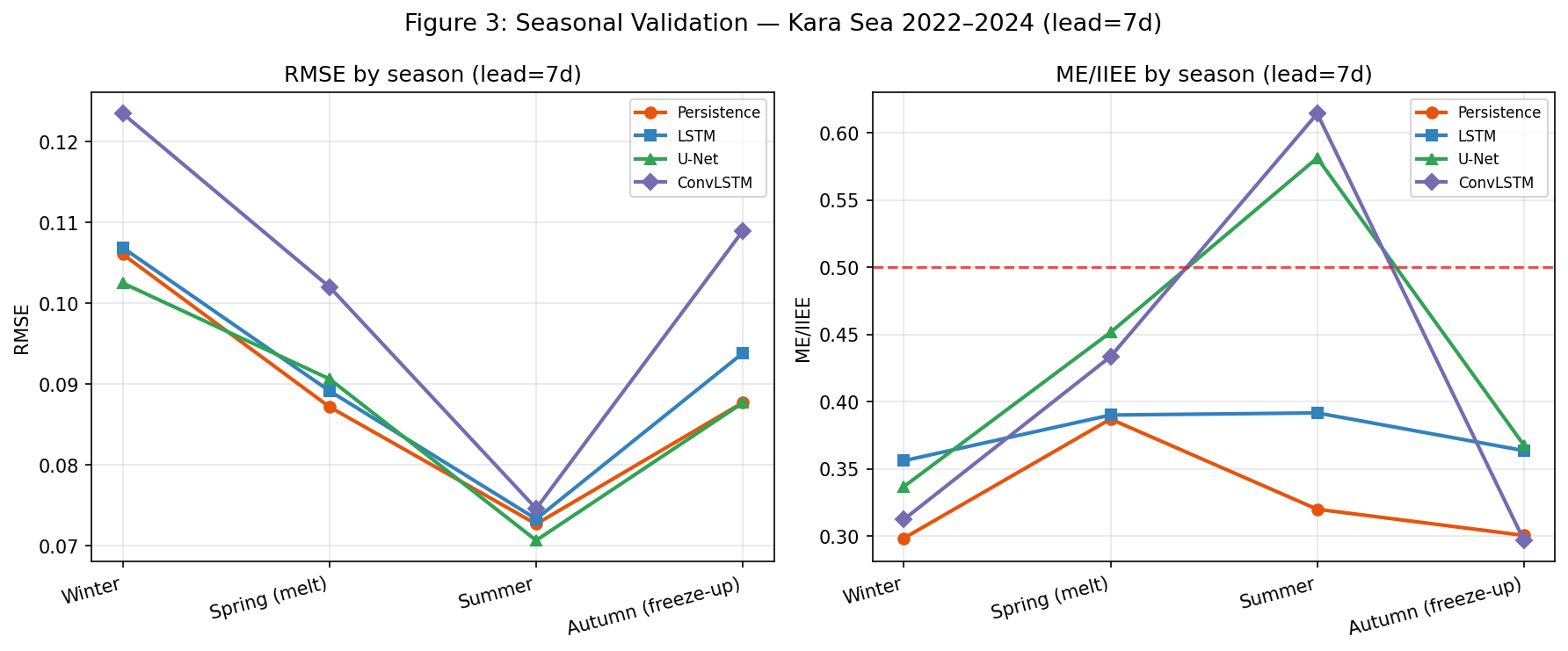
Сезонность тоже играет роль. Пик расхождений — переходные сезоны (октябрь–декабрь для замерзания, июнь–июль для таяния), когда кромка динамична. Зимой, когда Карское море покрыто льдом почти целиком, метрики согласованы — кромку просто некуда сдвигать.
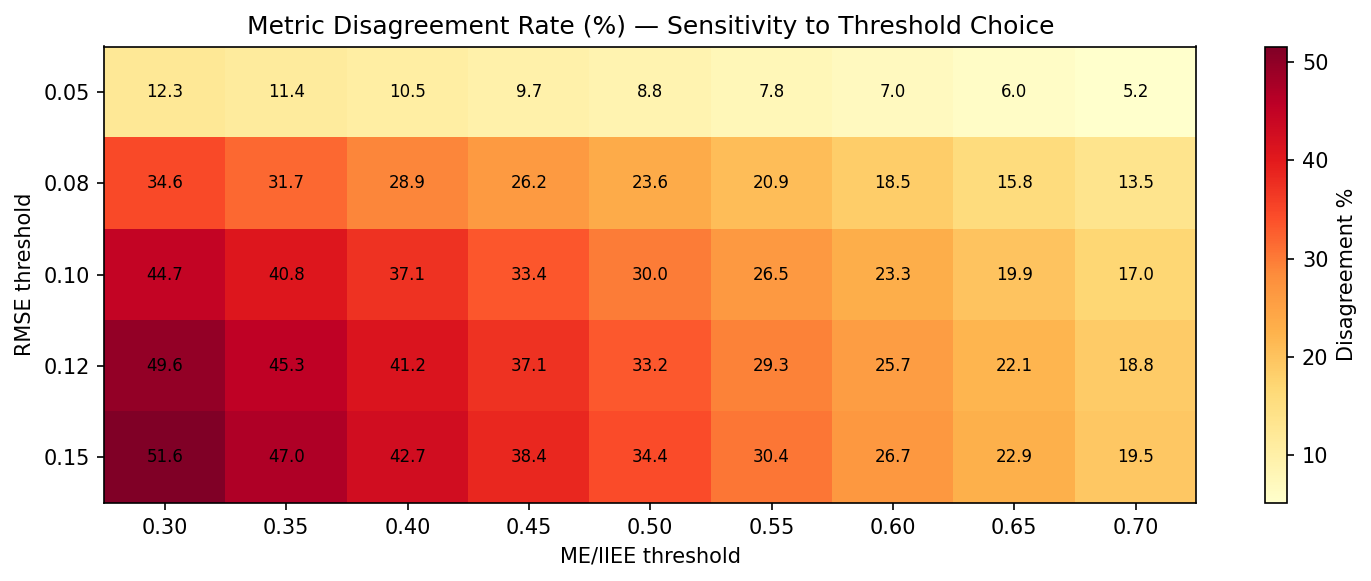
Тепловая карта чувствительности показывает, как результат зависит от порогов RMSE и $\text{ME}/\text{IIEE}$. Наш выбор (0.10 и 0.50) — не произвольный: это точка, где кривые доли расхождений стабилизируются. Сдвиньте RMSE-порог до 0.15 — процент расхождений снижается до 18%, но вы уже пропускаете откровенно плохие прогнозы.
Вывод прямой: нейросети с MSE-лоссом жертвуют кромкой ради средней ошибки. Это не баг конкретной архитектуры — это свойство функции потерь. MSE штрафует за средний квадрат отклонения по всем пикселям, а пиксели кромки — это тонкая полоска, которая тонет в массе «лёгких» пикселей открытой воды и сплошного льда.
Решение? Составные функции потерь, которые явно штрафуют за смещение кромки. Но это тема для отдельного поста (и отдельной главы диссертации).
Воспроизводимость: один клик до результата Ссылка на заголовок
Весь код, данные и ноутбуки — в открытом репозитории:
github.com/bolkhovsky/sea-ice-validation-titds2025
Что внутри:
notebooks/full_pipeline.ipynb— Google Colab-ready ноутбук, от загрузки данных до финальных фигур. Запускается в один клик, GPU не нужен.src/metrics.py— IIEE-декомпозиция и все вспомогательные метрики.src/visualization.py— четырёхпанельная фигура и все графики из статьи.data/checksums.sha256— SHA256-хеши всех входных файлов для верификации.
Данные OSI SAF — публичные, скачиваются скриптом из репозитория. Модели — предобученные веса лежат в релизах GitHub.
SHA256-верификация — не формальность. Мы столкнулись с тем, что ICDR-данные за один и тот же день могут отличаться в зависимости от версии продукта. Хеши фиксируют точный набор входных данных, на которых получены результаты в статье.
Если вы работаете со своей областью — замените bbox в конфиге, пересчитайте площадь ячейки для своей сетки, и пайплайн заработает. Код параметризован, привязка к Карскому морю — только в конфигурационном файле.
Есть вопросы по пайплайну или хотите адаптировать его для своего региона? Пишите в комментариях или открывайте issue в репозитории.